pgvector: 30x Faster Index Build for your Vector Embeddings
Parallel index builds for HNSW with pgvector

We are Neon, the serverless Postgres. We power thousands of AI apps with the pgvector extension and separate storage and compute enabling your database resources to scale independently. In this article, Raouf explains how you can use Neon’s elasticity, and parallel HNSW index build in pgvector (0.5.1 for now, and soon 0.6.0) to scale your AI apps.
Postgres’ most popular vector search extension, pgvector, recently implemented a parallel index build feature, which significantly improves the Hierarchical Navigable Small World (HNSW) index build time by a factor of 30.
Congratulations to Andrew Kane and pgvector contributors for this release, which solidifies Postgres’ position as one of the best databases for vector search and allows you to utilize the full power of your database to build the index.
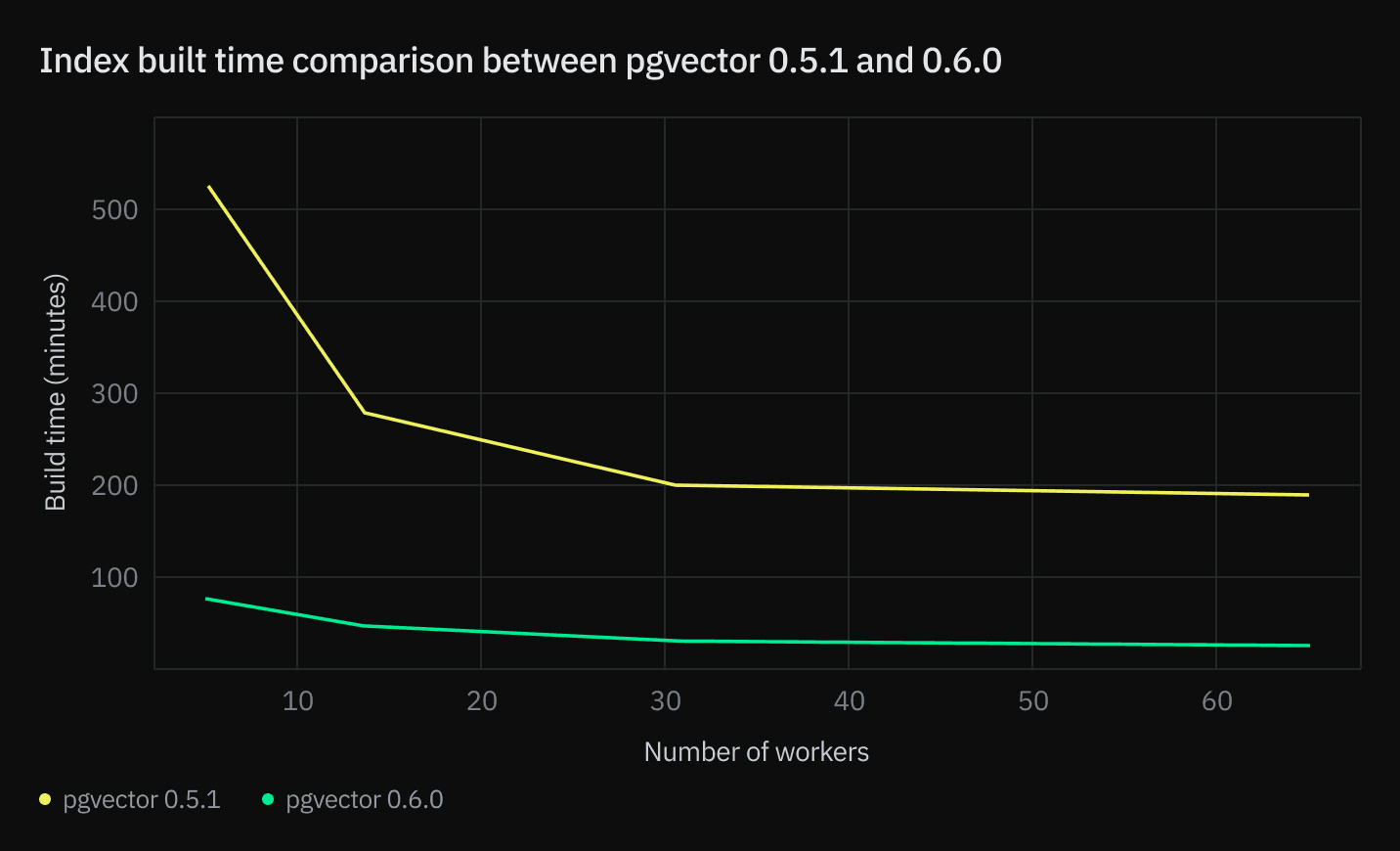
Tests run by Johnathan Katz using a 10M dataset with 1,536-dimension vectors on a 64 vCPU, 512GB RAM instance.
With Neon’s elastic capabilities and its architecture that separates storage and compute, you can, from the console or using the Neon API, allocate additional resources to your Postgres instance specifically for your HNSW index build process and then scale down to meet user demands, making Neon and pgvector a match made in heaven for efficient AI applications that scale to millions of users.
This article details how you can use pgvector with Neon.
The power of pgvector
Pgvector is Postgres’ most popular extension for vector similarity search. Vector search has become increasingly crucial to semantic search and Retrieval Augmented Generation (RAG) applications, enhancing the long-term memory of large language models’ (LLMs).
In both semantic search and RAG use cases, the database contains a knowledge base that the LLM wasn’t trained on, split into a series of texts or chunks. Each text is saved in a row and is associated with a vector generated by an embedding model such as OpenAI’s ada-embedding-002 or Mistral-AI’s mistral-embed.
Vector search is then used to find the most similar (closer) text to the query vector. This is achieved by comparing the query vector with every row in the database, making vector search hard to scale. This is why pgvector implemented approximate nearest neighbor (ANN) algorithms (or indexes), which conduct the vector search over a subset of the database to avoid lengthy sequential scans.
One of the most efficient ANN algorithms is the Hierarchical Navigable Small World (HNSW) index. Its graph-based and multi-layered nature is designed for billions-of-row vector search. This makes HNSW extremely fast and efficient at scale and one of the most popular indexes in the vector store market.
HNSW’s Achilles heel: memory and build time
HNSW was first introduced by Yu A Malkov and Dmitry A. Yashunin in their paper titled Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.
HNSW is a graph-based approach to indexing high-dimensional data. It constructs a hierarchy of graphs, where each layer is a subset of the previous one, which results in a time complexity of O(log(rows)). During the search, it navigates through these graphs to quickly find the nearest neighbors.

As fast and efficient as HNSW is, the index has two drawbacks:
1. Memory: The index requires significantly more memory than other indexes, such as the Inverted File Index (IVFFlat). You can solve the memory issue by having a larger database instance. But if you use standalone Postgres such as AWS RDS, you will find yourself in a position where you over-provision just for the index build. With Neon scaling capabilities, however, you can scale up, build the HNSW index, and then scale back down to save on cost.

2. Build time: The HNSW index can take hours to build for million-row datasets. This is mainly due to the time spent calculating the distance among vectors. And this is precisely what pgvector 0.6.0 solves by introducing Parallel Index Build. By allocating more CPU and workers, you build your HNSW index 30x faster.

But wait! The HNSW index supports updates, so why is this feature parallel index build necessary if you only need to build the index once?
Well, there are two cases where you need to create an HNSW index:
- When you want faster queries and to optimize for vector search
- When you already have an HNSW index, and you delete vectors from the table
The latter might cause the indexed search to return false positives, negatively impacting the quality of the LLM response and the overall performance of your AI application.
Scale up and boost index build time
pgvector 0.6.0 speeds up index build time up to 30 times compared to previous versions when using parallel workers. This improvement is especially notable when dealing with large data sets and vector sizes, such as OpenAI 1536 dimension vector embeddings.
Creating an HNSW index could require significant resources. The reason is you need to allocate enough `maintenance_work_mem` to fit the index in memory. Otherwise, the hnsw graph will take significantly longer to be built.
NOTICE: hnsw graph no longer fits into maintenance_work_mem after 100000 tuples
DETAIL: Building will take significantly longer.
HINT: Increase maintenance_work_mem to speed up builds.With Neon, you can scale up your Postgres instance using the Console or the API, configure it to build the index, and then scale back down to save on cost.
To effectively use parallel index build, it’s essential to configure Postgres with suitable settings. Key parameters to consider are:
maintenance_work_mem: This parameter determines the memory allocated for creating or rebuilding indexes. This parameter affects the performance and efficiency of these operations. Setting this to a high value, such as 8GB, allows for more efficient handling of the index build process.
SET maintenance_work_mem = '8GB';max_parallel_maintenance_workers: This dictates the number of parallel workers that can be employed. The default value of max_parallel_maintenance_workers is typically set to 2 in Postgres. Setting this to a high number enables the utilization of more computing resources for faster index builds.
SET max_parallel_maintenance_workers = 7; -- plus leaderNote: Neon supports for pgvector 0.5.1. However, our engineering team is working on adding support for 0.6.0. Stay tuned.
How does this affect recall performance?
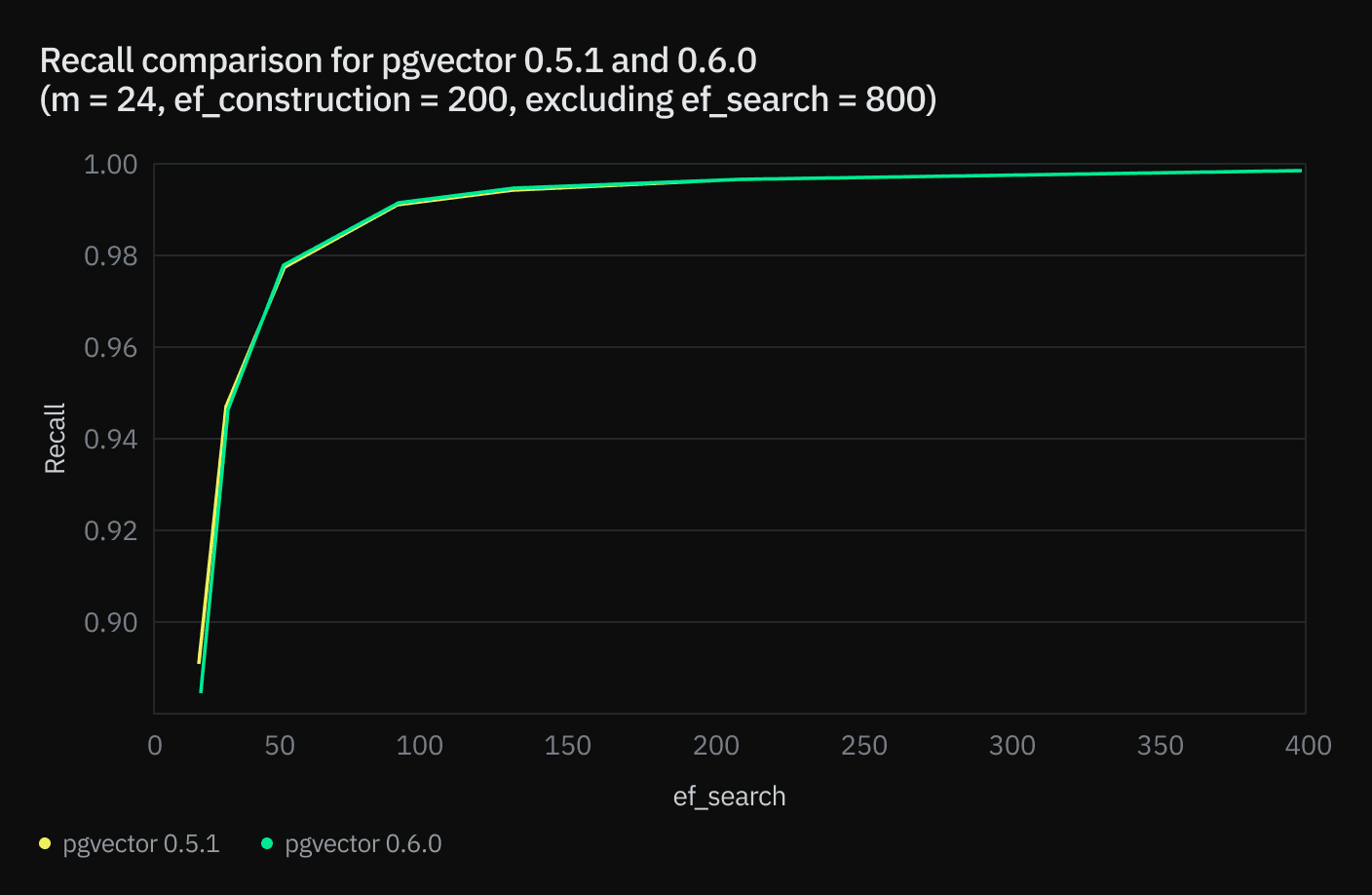
Recall is as important of a metric as query execution time in RAG applications. Recall is the percentage of correct answers the ANN provides. In the HNSW index, `ef_search` is the parameter that determines the number of neighbors to scan at search time. The higher `ef_search` is, the higher the recall and the higher the query execution time.
The tests conducted by Johnathan Katz show that using parallel builds has negligible impact on recall, with most changes swinging positively by over 1%. Despite the substantial speed improvements, this remarkable stability in recall rates highlights the effectiveness of pgvector 0.6.0’s parallel build process.
Conclusion
pgvector 0.6.0 represents a significant leap forward, proving that Postgres is an important player in the vector search space. By harnessing the power of parallel index building, developers can now construct HNSW indexes more rapidly and efficiently, significantly reducing the time and resources traditionally required for such tasks.
Neon’s flexible and scalable serverless Postgres offering complements pg vector’s capabilities perfectly. Users can scale their database resources according to their specific needs for index building and then scale down to optimize costs, ensuring an economical yet powerful solution.
What AI applications are you currently building? Try pgvector on Neon today, join us on Discord, and let us know how we can improve your experience with serverless PostgreSQL.



