Multi-tenancy and Database-per-User Design in Postgres
Getting ready to build your multi-tenant app in Neon
Many Neon users aren’t just storing their own information, but host data on behalf of many clients or customers, commonly called tenants. Over the decades, approaches to these multi-tenant data architectures have evolved in three main directions: shared schema, schema-per-user, and database-per-user.
With this first blog post, we’re starting a series dedicated to building database-per-user apps in Postgres and Neon. The serverless design of Neon, together with its hierarchy of instantly-deploying projects, branches, and databases, encourages some particular data architecture and application design patterns that aren’t always obvious upfront.
During the series, we’ll talk about the concepts and tools you can use to manage user databases effectively in Neon, and the ramifications this has on application development.
But first, let’s summarize the big-picture history.
If you’ve been here before, check out part II: Control Planes For Database-Per-User in Neon
How to store other people’s data in Postgres: the three multi tenant architectures
It’s a problem almost as old as the database itself: people want to see their data, they don’t (usually) want to see other people’s data, and they certainly don’t want other people seeing, let alone manipulating, their data. Failure to preserve the invisible boundaries between this user’s data and that user’s data is the stuff of which uncomplimentary news articles and lawsuits are made.
And yet, when multiple users create data in a given system, it’s structurally identical. The same schemata, and the same constraints apply to each set. From a security perspective, it’s smartest if no two users’ data are ever in the same place, but system architectures have to contend with finite resources and limits to manageable complexity. This is the fundamental tension that has given rise to the three primary multi-tenant architectures:
Database-per-user
Database-per-user architectures are perhaps the oldest, and in some sense simplest. They sidestep any possible problem of colocation by keeping each user’s data totally isolated.
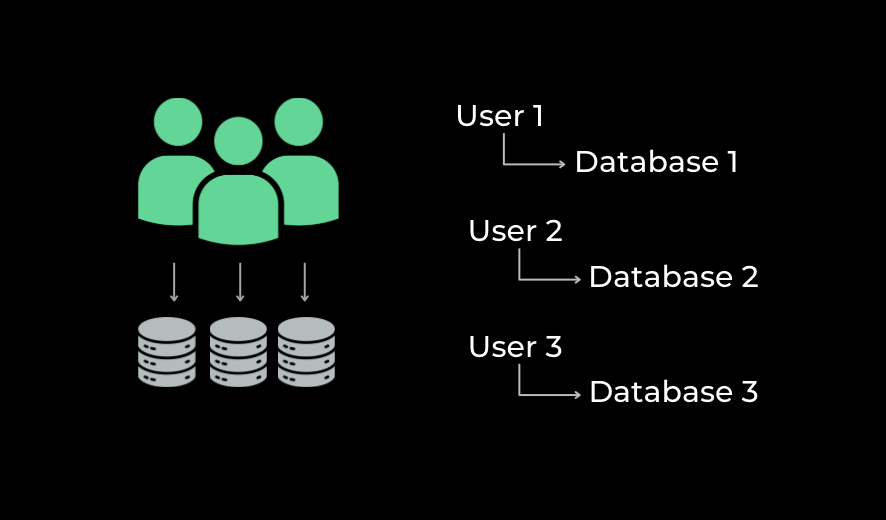
Typically, this design shifted that complexity rather than reducing it. Discrete databases have traditionally implied discrete application environments as well, and maintenance and especially upgrades have as many targets as you have users. Before the cloud era, database-per-user was easily the most expensive and operationally intensive option.Later on, we’ll discuss how this picture changes with Neon.
Schema-per-user
Schema-per-user architectures evolved as a cheaper version of database-per-user. Instead of isolating users in their own databases (and even potentially their own servers), these use a single database, but create a fresh copy of the system’s schema for each user.
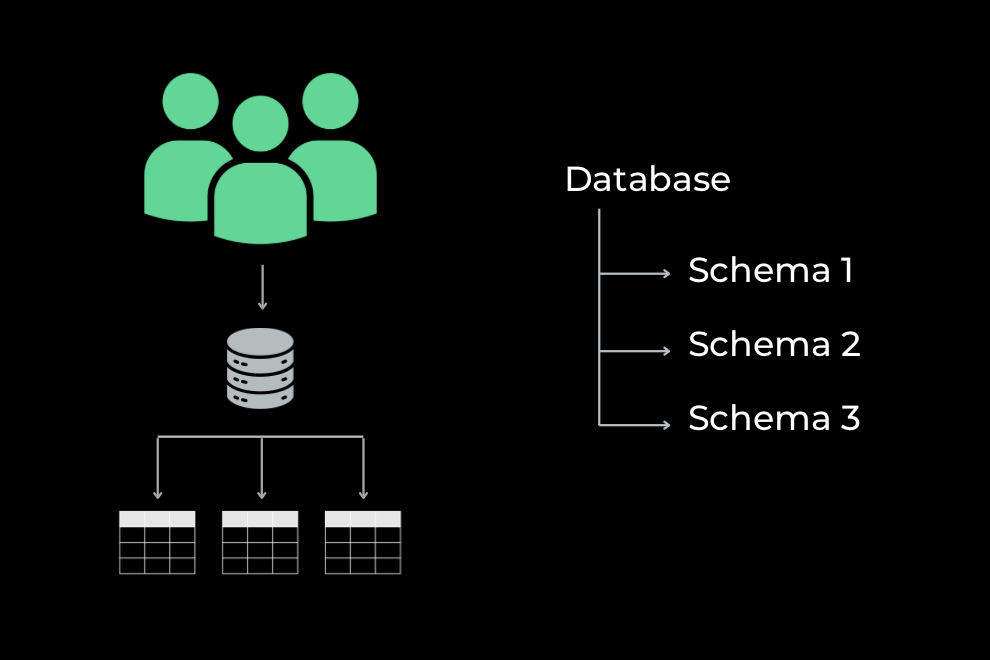
Unfortunately, this doesn’t do much to decrease the operational burden, and introduces some new risks compared to the stricter model. In the age of cloud databases, there’s little reason to recommend this approach.
Shared schema
Finally, the shared schema strategy puts everyone’s data side-by-side, taking advantage of foreign key constraints and, in more advanced iterations, row-level security, to guarantee data isolation. There are as many shared-schema architectures as there are security models; you can see a few examples here.
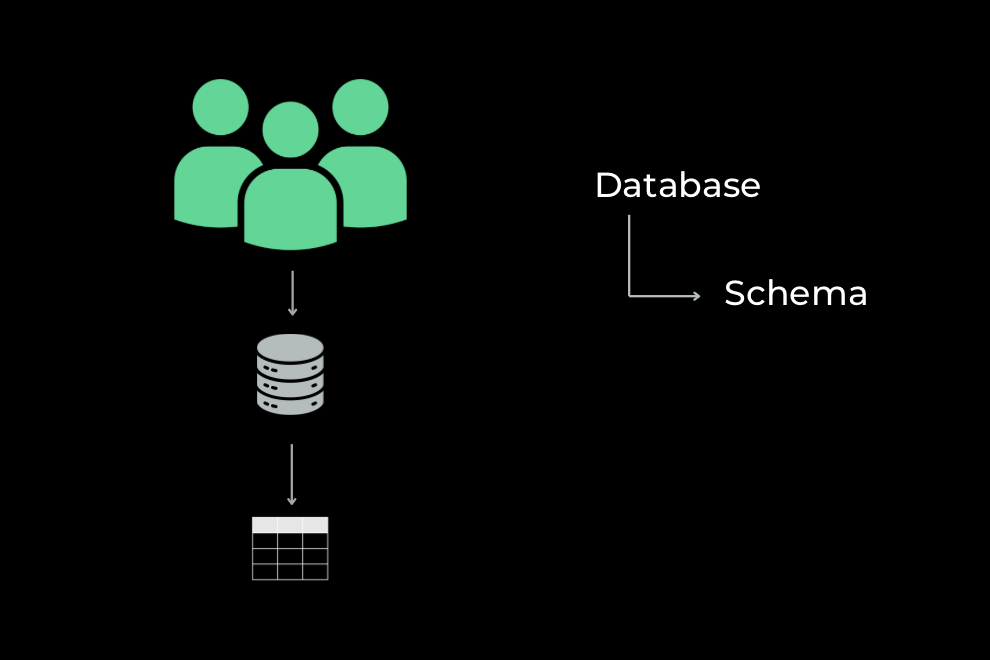
This design is both cheaper and generally easier to administer than the others; however, the risks of integrity violation are higher, and the consequences of such breaches are greater. Ensuring compliance and enforcing data access restrictions at the schema level can get more complex as the tenant base grows.
Why go database-per-user?
Completely isolated per-user databases aren’t just easier for application developers to reason about as they consider their security models. Some customers prefer deployments to be geographically close to their locations to minimize latency; some industries place a premium on isolation due to the sensitivity of the information involved; some countries outright forbid the storage of their citizens’ data outside their borders. Cases like these, and more, can make the database-per-user strategy the only reasonable solution.
But it isn’t entirely about the customer or their country of residence, either. In particular, what’s known as the noisy neighbor problem — where a few customers make up a disproportionate fraction of the system’s overall activity, and other customers suffer higher latencies, locks, and unavailabilities — can only be solved completely by moving the noisy neighbors to their own database servers where they can’t monopolize resources others need to access.
The database-per-user strategy has compelling advantages – the problem is that, historically, it has been expensive and difficult to manage. Some of those historical problems have become less acute as cloud technology has advanced; Neon’s architecture and feature set tackle others head-on, as we discuss later in this series when we dive into detailed system designs.
Of course, even with 21st century tools, database-per-user still involves some engineering investment. It’s hard to beat the simplicity of having only one thing to connect to, one thing to watch, one thing to upgrade — but it’s also true this “simplicity” tends to overshadow the effort involved in securing a shared database. In any case, the investment in database-per-user pays dividends: if done thoughtfully, you can reap the benefits of full data isolation and build operational tooling that helps manage and contain the complexity attending that isolation as you scale.
Database-per-user system design
Just like there are multiple possible architectures for multi tenant design, the database-per-user option can support multiple kinds of application systems. In fact, deploying a database for each customer begs a single, critical question: do you deploy one application environment per database as well, or connect all databases to a single application environment?
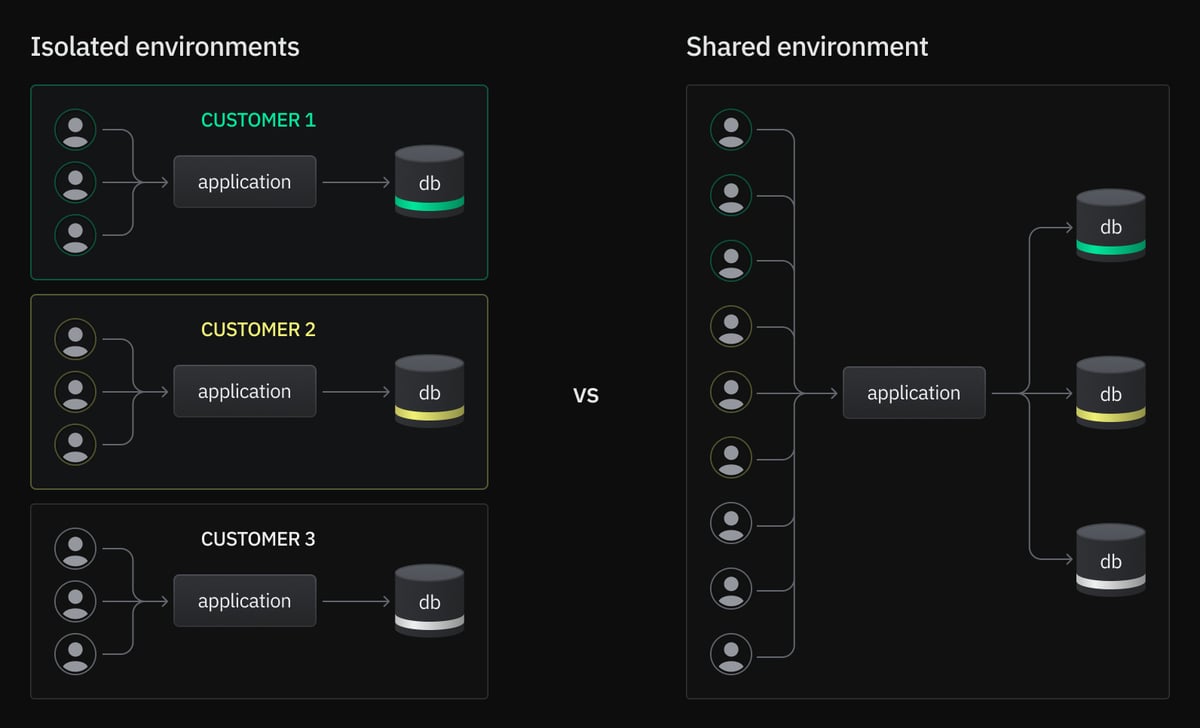
Isolated application environments
Isolated application environments keep customers well and truly separated. They’re conceptually simple — you’re effectively deploying a single-tenant application many times over — but this makes them more expensive and operationally more complicated. The complete separation does enable more flexibility, since environments can be deployed to different regions or held back to specific versions.
Shared application environment
A shared application environment is the typical “as a service” pattern and bears some surface similarities to the shared-schema multi tenancy strategy, which usually also supports a sole application instance serving all customers.
Like the shared-schema strategy, authorization is of paramount importance: the worst case scenario in both is the same, where a user sees information they shouldn’t. In exchange, having only one deployment enables more complex application architectures, and there’s less work involved in onboarding new customers.
| Need | In isolated environments | In shared environments |
|---|---|---|
| Data isolation | Absolute | Depends on user authorization |
Geographic restrictions on customer data | Always determined per customer | Data may reside in any region, but can result in higher latencies between the database and application that get passed on to the customer |
Onboard a new customer | Provision and deploy full software environment | Add customer database connection to single instance |
Keep customers at specific application versions | Upgrades are always per-customer | Not possible |
Add complex system components (rules or processing engines, data warehousing, third-party service integrations) | Manage independently in each environment | Deploy once |
Tailor application behavior or schema to individual customers | Possible, but almost always a bad idea due to added complexity | Not possible |
Control planes
Whichever route you take, as your application grows, maintaining a central control plane for operations becomes essential to scaling beyond the initial manual workflows. A control plane is crucial for automating and streamlining the complex tasks that come with managing multiple databases, ensuring you can scale effectively.
Originally a networking term, “control plane” referred to the routing rules over a “data plane” of packets. In the context of software, it means a system that enables engineers to provision and manage other software at scale. This control plane can handle a variety of tasks critical to multi-tenant applications:
- Onboarding: While platform-provided tools can spin up new databases, a control plane can automate the entire onboarding process, integrating with billing systems, applying schemas, setting up authentication, and triggering necessary deployments.
- Monitoring: Standard metrics like connectivity and resource usage are important, but a control plane allows you to track more granular details, such as schema versions, customer-specific configurations, and application performance across your entire database fleet.
- Maintenance: Centralized monitoring facilitates centralized operations. Tasks like scaling, suspending, or reactivating databases, managing branches, and executing schema upgrades become safer and more efficient when standardized through a control plane.
In future posts, we’ll explore how to build and manage such a control plane specifically for database-per-user applications using Neon.
Wrap-up
With either approach, the database-per-user fundamentals work the same way and offer the same advantages over other multitenancy strategies, especially with Neon.
Shared environments are simpler to operate, and enable more complexity within the single deployed environment, but this sacrifices some capabilities that may be important to you and your customers. Meanwhile, isolated environments offer much more power and flexibility, but at a price.
📚 Keep reading
Check out the second article of the series: Control Planes in Database-Per-User in Neon. You’ll learn how to implement an effective control plane to scale your multi-tenant application with efficiency and security.



